大多數投資人花 90% 的時間思考「買什麼」,卻幾乎不花時間思考「怎麼組合」。
這個比例,剛好顛倒了。
學術研究反覆告訴我們同一件事:長期決定投資績效的,不是你選中了哪支股票,而是資產配置的結構(Asset Allocation)——各類資產如何搭配、比例如何決定——這個決策,貢獻了超過九成的報酬變異。選股是有趣的,配置是枯燥的。但投資世界就是這樣殘忍:真正重要的事,往往不夠吸引人。
從一個數學問題說起
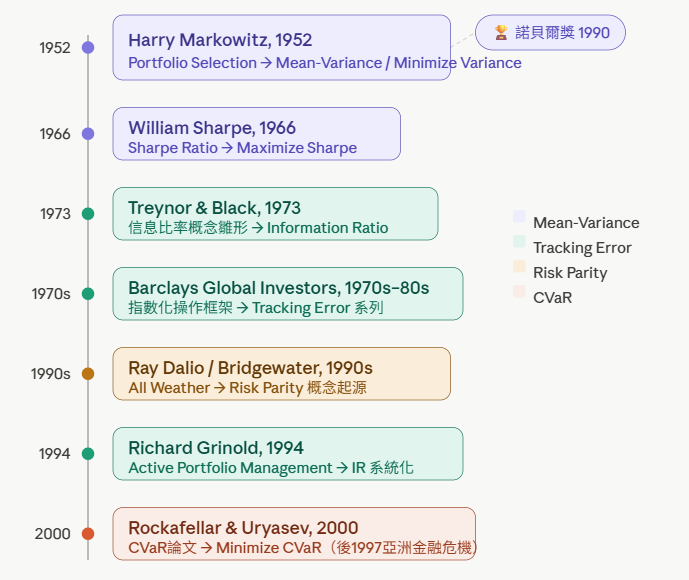
1952 年,Harry Markowitz 在一篇論文裡問了一個在此之前沒有人認真回答過的問題:
給定一組資產,怎樣的持倉比例,能讓投資人在承擔最少風險的前提下,獲得最高的報酬?
他的答案,是所謂的「有效前緣」(Efficient Frontier):在報酬與風險的座標上,存在一條曲線,曲線上的每一個點,都代表「在這個風險水準下,沒有比它更好的組合」。落在曲線下方的,叫做無效率的組合——你承擔了某程度的風險,卻沒有拿到對應的報酬。
這個框架奠定了現代投資組合理論(Modern Portfolio Theory, MPT)的基礎,也讓 Markowitz 在三十八年後拿到了諾貝爾獎。但它同時開啟了一個更大的問題:這個框架需要你輸入「預期報酬」。而預期報酬,恰恰是金融世界裡最難預測的東西。
這個根本的脆弱性,催生了七十年的演化。
七十年的演化:每個時代的傷疤
每一個新方法的誕生,背後都是一場危機與一個舊框架無法解釋的現實。
1966 年,William Sharpe 提出以「每單位風險的報酬」——夏普比率(Sharpe Ratio)——作為衡量組合效率的指標,有效前緣上的切線組合從此有了名字。
1970 年代,大規模機構委外管理興起,追蹤誤差(Tracking Error)與信息比率(Information Ratio)成為評估主動管理能力的行業語言。
1997 年亞洲金融危機與 1998 年 LTCM 事件,暴露了標準差無法捕捉肥尾風險(Fat Tail Risk)的致命缺陷,促使 Rockafellar 與 Uryasev 在 2000 年正式提出條件風險值(CVaR, Conditional Value-at-Risk)。
2008 年金融海嘯後,Ray Dalio 的 Bridgewater 以風險平價(Risk Parity)示範了一種不依賴報酬預測的配置哲學。
每一個方法,都是某一個時代的答案。
七種方法,七種取捨
1|最大化夏普比率(Maximize Sharpe Ratio)
在每一單位風險中爭取最高報酬,是有效前緣上的切線組合。理論嚴謹、概念清晰,但對預期報酬的輸入極度敏感——估計稍有偏差,便可能產生高度集中的極端持倉。在實務中,通常需要搭配持倉上下限(Box Constraint)才能落地執行。
2|給定風險上限,最大化報酬(Maximize Return subject to Risk Constraint)
先設定波動率(Volatility)上限的硬性紅線,在紅線之內追求最高報酬。這是法規或合約約束轉化為數學語言的直接產物,適合有明文規定風險上限的機構。缺點同樣是依賴報酬預測,且若上限設得過緊,組合會不自覺地向債券傾斜。
3|最小化變異數(Minimize Variance)
完全放棄報酬預測,只求波動最低。看似保守,實則有一個反直覺的優勢:它是模型假設最少、對估計誤差最不敏感的均值-變異數方法。實證研究亦一再發現,低波動組合的長期報酬往往不遜於高波動組合——這是所謂的「低波動異常」(Low Volatility Anomaly)。
4|最小化追蹤誤差(Minimize Tracking Error)
以複製基準指數(Benchmark)為目標,把主動偏離壓到最低。這是被動管理與指數投資的核心邏輯,成本低、透明度高,代價是 Alpha 空間幾乎為零。
5|最大化信息比率(Maximize Information Ratio)
信息比率 = 超額報酬(Alpha)÷ 追蹤誤差,衡量每承擔一單位主動風險所換來的超額報酬。這是主動管理的核心語言,也是最誠實的一個框架——它要求投資人必須先回答:我們真的有可信的 Alpha 來源嗎?
6|給定追蹤誤差預算,最大化超額報酬(Maximize Excess Return subject to TE Constraint)
在委託合約規定的追蹤誤差上限(TE Budget)之內,追求最大的超額報酬。這是機構 OCIO 委託管理的實務語言,直接對應合約條款,讓受託人與委託人都有清晰可稽核的共同依據。
7|最小化條件風險值(Minimize CVaR)
不問平均波動,只問極端情境下的預期損失——即「在最壞的那 5% 或 1% 情境下,平均損失是多少」。這是標準差家族無法回答的問題,適合持有高收益債、私募信用等非常態分佈資產的組合。溝通難度較高,但對尾部風險的描述遠比標準差更誠實。
8|風險平價(Risk Parity)
讓每一種資產對組合總風險的貢獻相等,不依賴任何報酬預測。核心精神是謙遜:既然我們無法可靠地預測哪個資產會漲,就讓風險均勻分散。代價是天生低配股票,若要達到目標報酬通常需要加槓桿,在利率急升環境下(如 2022 年)表現會承壓。
綜合比較
| 方法 | 最佳化目標 | 需要報酬預測 | 風險衡量 | 主要優點 | 主要限制 | 最適情境 |
|---|---|---|---|---|---|---|
| 最大化夏普比率 | 報酬 ÷ 風險最大 | ✅ | 標準差(σ) | 理論嚴謹、概念清晰 | 對預測誤差極敏感;易集中持倉 | 避險基金;報酬預測信心高的情境 |
| 最大化報酬(含風險上限) | 給定 σ 上限下報酬最大 | ✅ | 標準差(σ) | 直接對應法規或合約約束 | 依賴報酬預測;上限過緊則喪失多元化 | 有波動率限制的機構,如員工福利信託 |
| 最小化變異數 | 波動最小 | ❌ | 標準差(σ) | 模型假設最少;低波動異常支持長期表現 | 易過度集中低波動資產;犧牲成長潛力 | 保守型機構;市場高度不確定時期 |
| 最小化追蹤誤差 | 貼近指數 | ❌ | 追蹤誤差(TE) | 成本低、透明、可預測 | Alpha 空間幾乎為零 | 被動管理;Smart Beta ETF |
| 最大化信息比率 | Alpha ÷ TE 最大 | ✅ | 追蹤誤差(TE) | 主動管理效率最高 | 依賴可信 Alpha 來源;預測誤差影響大 | 主動型基金;機構 OCIO 委託管理 |
| 最大化超額報酬(含TE上限) | 給定 TE 上限下 Alpha 最大 | ✅ | 追蹤誤差(TE) | 直接對應 TE Budget 合約條款 | TE 上限過緊時主動空間趨近於零 | 大學捐贈基金;退休金 OCIO 合約 |
| 最小化 CVaR | 極端損失最小 | 可選 | 條件風險值(CVaR) | 捕捉肥尾風險;更貼近實際損失感受 | 需大量數據或模擬;溝通難度高 | 含高收益債、私募資產的組合;金融機構監管需求 |
| 風險平價 | 風險貢獻均等 | ❌ | 風險貢獻比例 | 不依賴預測;多元分散效果佳 | 需加槓桿才能達標;利率上升時承壓 | 多資產全天候策略;對預測失去信心時 |
選擇的起點:三個關鍵問題
面對八種方法,選擇的邏輯可以收斂到三個問題:
一、你對預期報酬的估計,有多少誠實的信心?
信心高 → 均值-變異數(Mean-Variance)家族或信息比率框架。
信心低 → 最小化變異數、CVaR、或風險平價。
二、你有沒有基準指數(Benchmark)需要對齊?
有 → 追蹤誤差(Tracking Error)家族。
沒有 → 均值-變異數或超越變異數的方法。
三、你最擔心的是平均波動,還是極端損失?
平均波動 → 標準差類方法。 極端損失 → CVaR。
兩者皆擔心 → 混合架構,以主方法搭配 CVaR 作為尾部風險護欄。
阿爾發 AI 投資長如何運用這些方法
阿爾發 AI 投資長的核心哲學,奠基於「策略性被動資產配置」(Strategic Passive Asset Allocation)——我們相信,長期決定投資成果的,不是擇時進出或選股,而是一開始就建立正確的組合結構,然後有紀律地持守它。
這個哲學看似簡單,執行卻極為困難。困難不在於數學,而在於人。市場每一次的劇烈波動,都在考驗投資人能否不偏離原定的配置框架。AI 投資長存在的意義,正是在這個過程中,排除情緒干擾,忠實執行長期策略。
在了解你這件事上, AI 投資長透過系統性的目標設定與風險屬性分析(Risk Profiling),將每一位投資人的財務目標、投資期限、流動性需求與真實風險承受能力,轉化為一份清晰的投資計畫(Investment Policy Statement)。這份計畫不是問卷填完就束之高閣的文件,而是整個投資組合建構與後續決策的根本依據。
在建立組合這件事上, AI 投資長依據投資計畫,從全球多資產的角度出發,運用上述最佳化框架,為每一位投資人量身建立最符合其目標與約束條件的策略性資產配置(Strategic Asset Allocation, SAA)。組合一旦建立,結構本身就是最重要的護城河——我們不依賴對市場走向的預測,而是依賴多元分散與時間複利的力量。
在維護組合這件事上, 隨著時間推移,市場漲跌會使各資產的實際比例偏離原定配置。AI 投資長持續監控組合的漂移狀況,在適當時機執行再平衡(Rebalancing),將組合拉回策略性配置的軌道。這個動作看似機械,背後卻蘊含著一個深刻的紀律:在市場最熱的時候減碼,在市場最冷的時候補倉。 這正是大多數投資人因情緒而做不到、卻又最能創造長期價值的事。
對機構法人委託人——無論是大學校務基金、企業退休信託或員工福利信託——阿爾發進一步將上述流程對應至各自的政策組合(Policy Portfolio)、法規約束與花費規則(Spending Rule),提供完整的客製化配置架構。每一個組合背後,都有一套從委託人真實目標出發、嚴謹建構而成的長期投資計畫。
投資的本質從來不是找到最聰明的方法,而是建立一個你能長期執行的結構——然後讓時間替你工作。